This one was a real facepalm moment, but I thought I’d share in case anyone else runs into the same thing.
I’ve been working on migrating from Nagios to Icinga2. One of the services I monitor is whether or not a given host has any available yum updates. This service, which I label check_yum, worked on all my hosts except for the Icinga2 host. All the other services monitored on that host were working, but check_yum returned an error:
NRPE: Unable to read output
I tried running the test manually on the Icinga2 host:
/usr/lib64/nagios/plugins/check_nrpe -H localhost -c check_yum
NRPE: Unable to read output
I checked to make sure NRPE was listening, in this case via xinetd:
lsof -i
I checked the service definition to see what script/plugin NRPE runs:
The sudo command on one particular FreeIPA-bound host was taking an exceedingly long time to run. And when it finally ran, it would not accept my current password, but rather my previous password — somehow still cached on the system. It was a strange problem.
Instead of trying to figure out exactly why it was happening, I decided to remove & re-bind the host to my FreeIPA domain. Continue reading Re-bind host to FreeIPA
I made a lot of mistakes trying to get this to work (probably because I didn’t read the documentation!), so I’ve included all my steps and missteps below in case they are useful to someone else: Continue reading Javascript Unit Tests with TravisCI and QUnit
I’m looking at starting another blog at impractical.bot, as a home for my impractical chatbots. I thought I should check out a blog software other than WordPress, since all of my infosec colleagues make fun of me for using it. One option on my list is Jekyll, which builds static sites. That’s great if you are worried about resources (i.e. super-cheap hosting) and security.
The Jekyll site includes a 4-step quickstart. Unfortunately, it failed for me at step #1:
Error installing jekyll, failed to build gem native extension
I’m running this on a Fedora 27 virtual machine that I spun up for testing Jekyll:
The following steps in Jekyll’s quickstart worked too:
$ jekyll new my-awesome-site
$ cd my-awesome-site
$ bundle exec jekyll serve
I copied my ~/my-awesome-site/_site folder to my document root (this can be automated with Jekyll, but I’m not there yet), and now, voila! my site is live: http://impractical.bot
I’m migrating scripts from one CentOS host to another. (The old one is CentOS 6 and the new one is CentOS 7.) One of the items I want to move is a script that’s part of a git repo.
I know it’s a git repo because it has a .git directory. The directory and files are owned by a local user, luser1.
Where did this git repo come from?
You can call git config -l and it will tell you things about the repo, including the remote.origin.url. Now I can tell that it came from my GitHub Enterprise (GHE) instance.
But it doesn’t tell you who created it. And luser1 doesn’t exist on my GitHub Enterprise instance.
I tried to clone it on the new host, just to see what would happen:
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
Somehow luser1 is able to interact with this repo on the old host, even though the user doesn’t exist in GHE.
Fortunately the local repo has some history:
$ head -n1 .git/logs/HEAD
Result:
0000000000000000000000000000000000000000 ab509345a16d987dac10987c4bc2df0c0dfb3ed9 luser1 luser1 <luser1@oldhost.osric.net> 1505633110 -0500 clone: from git@github.osric.net:team1/the-sauce.git
Right there there it is, all the info I wanted! Except that’s the same user, the user that doesn’t even exist in GitHub Enterprise.
Or does it? I went looking at some of the other users in my GitHub Enterprise instance. There were a few system accounts, and when I checked some of them had several SSH keys associated with the accounts. One of the SSH key fingerprints even said luser1.
I wanted to compare that key fingerprint to the key in /home/luser1/.ssh/id_rsa.pub. I can never remember how to do that, but StackOverflow had the answer on How do I find my RSA key fingerprint?
I had been using the Python socket module to create a very basic client-server for testing purposes, but soon I wanted to have something slightly more standard, like an HTTP server. I decided to try the Python Flask framework.
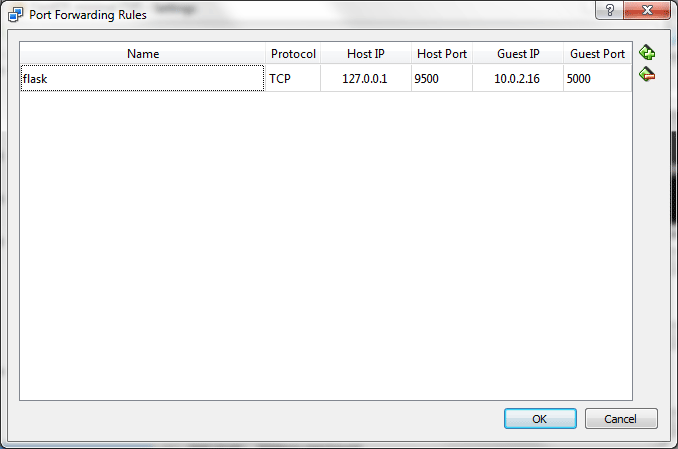
First I set up a Flask server on a CentOS 7 Linux VM running on VirtualBox:
Obviously, if you are dealing with a machine connected directly to the Internet, this would be a terrible solution. You’d want to add rules allowing only the hosts and ports from which you expect to receive connections. But for testing communications between my desktop and a virtual host running on it, this seemed like a quick solution.
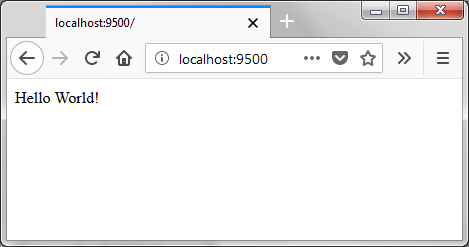
After those 2 changes, I was able to load the sample “hello” Flask app in a browser:
In the previous post, Converting a CVS project to a Git repository, I describe using cvs2git to convert a CVS project to a git repository. After I made the conversion, I wanted to make the CVS project read-only.
There’s probably no reason to keep the CVS project around (the history is in the git repo, and I have backups of the CVS project), but it felt like the right thing to do. The blog post Read-only CVS access for only certain projects was extremely helpful to accomplish this.
The key component is the CVSROOT/commitinfo file within your CVS repository. Like any other project in CVS, you need to check this out to make changes:
cvs co CVSROOT
cd CVSROOT && vi commitinfo
You specify a regular expression and a script to run before committing data to a project matching that regular expression. If the script exits with a non-zero exit code (indicating an error), the commit is aborted. For initial testing, I used false (or /bin/false) for the script component, which does nothing and returns an exit code of 1.
I had some problems with this, in part because I was not sure what the project string would look like. I tried a few things:
^/testrepo/.* false (didn’t work)
^testrepo/.* false didn’t work
^t.* false worked, but would match other projects as well
Eventually I switched to using the read-only-project.sh example from the aforementioned blog post, which printed out the values of the project path and the filenames to be committed.
From there I could see that the project path:
Does not include an initial slash
Does not include a trailing slash
May include additional slashes if the project contains subdirectories
The same script suggests including the following in commitinfo:
^projectname/.* /path/to/script "%p" %s
That regular expression does not work — it would match a file at projectname/subdir1/file1 but not projectname/file1.
Currently, if no format strings are specified, a default string of ` %r/%p %{s}’ will be appended to the command line template before replacement is performed, but this feature is deprecated.
Fortunately, the cvs2svn project includes cvs2git. The instructions included are good, but here are a few things I ran into that may be useful:
You need the actual CVS repo, not a checked out copy. If you run cvs2git on a checked-out copy, you will get an error message like:
ERROR: No RCS files found under 'projectname'
I found that mentioned on svn2git fails “ERROR: No RCS files found under…”. A comment there mentions getting a tarball of your project from Sourceforge, but if you aren’t working with a Sourceforge project, make your own tarball:
tar -cf cvs.tar.gz /path/to/CVS
I created a tarball because I am not running cvs2git on the same machine as my actual CVS repo. cvs2git is non-destructive, and I have backups in case something goes wrong, but I didn’t feel like taking any risks (or testing my restore procedures) at that moment.
I ended up running cvs2git on a Fedora VM. First, install CVS:
sudo dnf install cvs
Install cvs2svn:
wget http://cvs2svn.tigris.org/files/documents/1462/49543/cvs2svn-2.5.0.tar.gz
tar -xf cvs2svn-2.5.0.tar.gz
cd cvs2svn-2.5.0
make install
Create the blob and dump files (you’ll import these into git shortly):
(It’s still a bare repo locally, so if you want to check it out you can clone it out to another destination folder, or rm -rf the local repo and clone it.)
The last thing I wanted to do: make the current CVS project read-only. That turned out to be more confusing than I expected, so I’ve turned that into a separate post, Make a CVS project read-only.
I have a monolithic Ansible playbook that contains dozens of different roles, all bundled into the same Git repository. Some of the roles are more generically useful than others, so I thought I would do some refactoring.
I decided to move the role that installs and configures fail2ban to its own repository, and then call that new/refactored role as a dependency in my now-slightly-less-monolithic role.
One thing that I do frequently with an Ansible role is check to see if software is already installed and at the desired version. I do this for several related reasons:
To avoid taking extra time and doing extra work
To make the role idempotent (changes are only made if changes are needed)
So that the play recap summary lists accurate results
I’m thinking particularly of software that needs to be unpacked, configured, compiled, and installed (rather than .rpm or .deb packages). In this example, I’ll be installing the fictional widgetizer software.
First I add a couple variables to the defaults/main.yml file for the role:
The command task normally reports changed: true, so specify changed_when: False to prevent this.
Although this task should only run if widgetizer is present, we don’t want the task (and therefore the entire playbook) to fail if it is not present. Specify failed_when: false to prevent this. (I could also specify ignore_errors: true, which would report the error but would not prevent the rest of the playbook from running.)
Now I can check the registered variables to determine if widgetizer needs to be installed or upgraded:
- name: install/upgrade widgetizer, if needed
include: tasks/install.yml
when: "not result_a.stat.exists or widgetizer_target_version is not defined or widgetizer_target_version not in result_b.stdout"
tags: widgetizer
However, when I ran my playbook I received an error:
$ ansible-playbook -i hosts site.yaml --limit localhost --tags widgetizer
...
fatal: [localhost]: FAILED! => {"failed": true, "msg": "The conditional check 'not result_a.stat.exists or widgetizer_target_version is not defined or widgetizer_target_version not in result_b.stdout' failed. The error was: Unexpected templating type error occurred on ({% if not result_a.stat.exists or widgetizer_target_version is not defined or widgetizer_target_version not in result_b.stdout %} True {% else %} False {% endif %}): coercing to Unicode: need string or buffer, float found\n\nThe error appears to have been in '/home/chris/projectz/roles/widgetizer/tasks/install.yml': line 3, column 3, but may\nbe elsewhere in the file depending on the exact syntax problem.\n\nThe offending line appears to be:\n\n\n- name: copy widgetizer source\n ^ here\n"}
The key piece of information to note in that error message is:
need string or buffer, float found
We’ve supplied widgetizer_target_version as 1.2 (a floating point number), but Python/jinja2 wants a string to search for in result_b.stdout.
There are at least 2 ways to fix this:
Enclose the value in quotes to specify widgetizer_target_version as a string in the variable definition, e.g. widgetizer_target_version: "1.2"
Convert widgetizer_target_version to a string in the when statement, e.g. widgetizer_target_version|string not in result_b.stdout
After making either of those changes, the playbook runs successfully and correctly includes or ignores the install.yml file as appropriate.