I had the idea of applying Scrabble scores to DGA domains over the summer of 2018, but the idea was rekindled when I saw Marcus Ranum‘s keynote at BroCon 2018. He talked about the advantages of scoring systems: they are fast, they are simple, and they can be surprisingly effective.
Domain Generating Algorithms (DGAs)
Malware uses DGAs to generate hundreds or thousands of new domain names daily. The malware then attempts to contact some or all of the domains. If a successful attempt is made to a control server, the malware will receive new instructions for malicious activity. The people and systems managing the malware need only register one new domain a day, but a defender would have to anticipate and/or discover thousands a day. To read more about DGAs, I recommend these articles from Akamai:
- What Are Domain Generation Algorithms (DGAs) and Why Should You Care?
- A Death Match of Domain Generation Algorithms
- Spotlight on Malware DGA Communication Technique
Scrabble Scores and DGAs
I’ve noticed that some, not all Domain Generating Algorithms produce unreadable domains like:
rjklaflzzdglveziblyvvcyk.com
It doesn’t look like a normal domain name, but is there a way a computer can reliably differentiate between that and a normal domain name? I noted that it’s loaded with high-value Scrabble letters like z, y, and k. I calculated the Scrabble score of the domain, assigning a score of 1 to all non-alphabetic characters (in this case, the dot).
That above domain, including the dot-com TLD, has a length of 28, a Scrabble score of 101, and an average Scrabble score per letter of 3.7. I hypothesized that normal domain names would have lower average per-letter scores.
When I introduced my plan to a colleague, he called it poor man’s entropy. Which it is! But it is also very fast and can be (presumably) calculated at line speed.
The Experiment
I took the Majestic Million — the top one million sites on the web — as my control group, and a list of 969 DGA domains harvested from @DGAFeedAlerts as my experimental group. Keep in mind that the Majestic Million still contains sites like michael-kors-handbags.com: highly questionable sites, but that are probably not generated by an algorithm.
I created and ran a script (available at https://github.com/cherdt/scrabble-score-domain-name) on the domains from both groups, calculating the length (total number of characters), the Scrabble score (assigning 1 to non-alpha characters), and the average Scrabble score per letter (Scrabble score/Length) for each domain.
Average Scrabble Score Per Letter
I initially thought the average Scrabble score per letter would be a superior measure. I didn’t want to penalize lengthy domain names. After all, I once registered, on behalf of a friend, the domain name theheadofjohnthebaptistonaplate.com. It’s ridiculously long and has a total score of 68, but an average per letter score of just 2.0.
It quickly became apparent that this is not a useful measure. Here are 3 short, legitimate domains that have high average per letter scores:
- qq.com (a popular messaging platform in China) has an average per letter score of 5.4
- xbox.com (the gaming console) has an average per letter score of 3.9
- xkcd.com (a popular web comic) has an average per letter score of 3.6
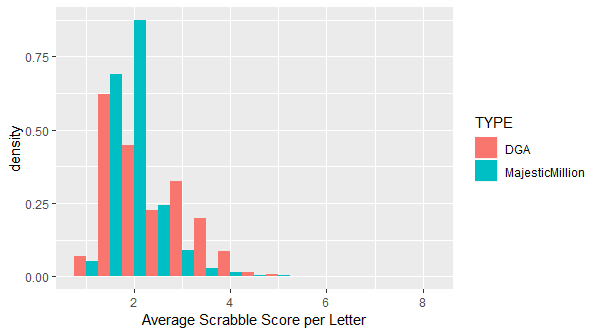
The goal of any such calculation would be not just to identify DGA domains, but to investigate or block them. qq.com is, according to the Majestic Million as of 20 November 2018, the 49th most popular domain on the Internet. Blocking or manually investigating domains based on high average scores alone would not be advisable.
Both of those domain names are very short though. What about some combination of average per letter score and length, such as the total Scrabble score?
Total Scrabble Score
The highest total Scrabble score in the Majestic Million is xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.com, with a score of 359. This is higher than the highest score on my DGA domain list: pibcjbpzdqzhvklfkbrsfuhyayfy.biz, with a score of 125. It’s still possible that a legitimate, although unusual, domain name could exceed the DGA domain scores.
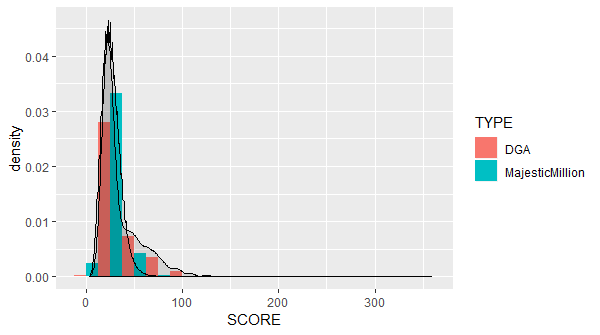
From the above graph, it looks like a Scrabble score of 75 or above is indicative of a DGA domain, right? Well, yes and no: recall that the sample size of DGA domains is 969, compared to the Majestic Million. Taking into account only domains with Scrabble scores of 75 or above:
- 1045 Majestic Million domains (about 0.1%)
- 56 DGA domains (about 5.8%)
If a 0.1% false positive rate and a 5.8% true positive rate are acceptable, then this is potentially actionable information. I suspect that in some environments, such as corporate networks, that might be acceptable. You might block a few legitimate sites, like highperformancewindowfilmsbrisbane.com.au, but on the whole that might be worth it to block malicious Command & Control (sometimes referred to as C2, CnC, or C&C) domains.
Variance in Command & Control DGA Domains
The 969 DGA domains I analyzed are related to 21 different C2 sources, and not all of them look the same. The first example I used, rjklaflzzdglveziblyvvcyk.com, is a Qakbot domain. Suppobox, on the other hand, combines 2 random words to create domains such as:
- callfind.net
- desireddifferent.net
- eveningpower.net
Not only do the Suppobox domains have low Scrabble scores, they aren’t even obviously unusual to a human observer. Automatically detecting Suppobox domains would be difficult. On the other hand, eliminating Suppobox and similar algorithms from the sample may make identifying other DGA domains easier.
I selected 5 C2 DGAs that appeared to have high-entropy domain names: Bedep, Murofet, Necurs, P2pgoz, and Qakbot. This subset included 244 DGA domains:
- 34 Bedep domains
- 14 Murofet domains
- 176 Necurs domains
- 14 P2pgoz domains
- 6 Qakbot domains
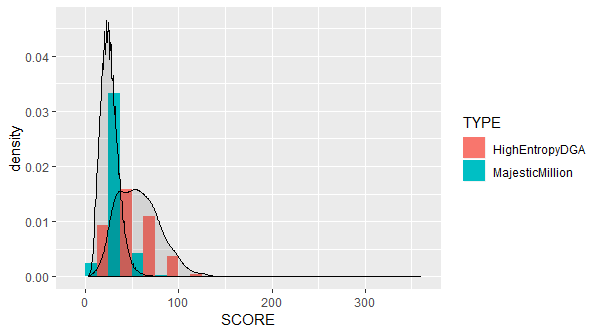
If we keep the Scrabble score threshold at 75, the number of false positives will remain the same: 1045. However, the number of true positives is 51. For the 5 selected DGAs, the true positive rate is now, or 21%. Still far from perfect, but potentially worth trying.
Further Discussion
It is likely that any such naive approach will become less and less effective as malware, such as Suppobox, uses DGAs that are more difficult to detect.
While analyzing these data, I had several ideas for less naive approaches and additional analyses, including machine learning techniques (binary logistic regression, principal components analysis), but I will save that exploration for a future post.
A much simpler filter to identify DGA domains would be to look for the
.pwTLD..pwdomains.pwdomainsThis is due almost entirely to Necurs. 139, or 79%, of Necurs domains in my sample were
.pwdomains.Using Scrabble scores is a biased, Anglo-centric approach. Polish has a preponderance of high scoring Scrabble letters like j, k, w, y, and z.
55 domains in Poland’s TLD (
.pl) from the Majestic Million had Scrabble scores of 75 or above.